


To start with, is it OK if I open my heart and say that for many years I just wrote articles and books and focused exclusively on (.NET and Windows) technologies? Yes, that was my career up until a decade ago, and it lasted that way for quite a few years. Repeatedly, people asked at conferences how I was able to squeeze time for real work in the flood of writings I was producing at an amazing pace. The answer was, I don't do much consulting; I only write. The reply engaged some people and left them wondering how was it possible for a human being to focus on writing, not doing real work, and still be able to specifically address real world issues. That was the (scrupulously kept) trade secret.
The entire building of my career threatened to collapse the day that my then seven-year-old son who, at the end of a nightly call with a friend about the schedule of a conference in Milan, just asked: Dad, what exactly is what you called a business layer?
Oh my God! How can an adult developer explain the concept of a business layer to a seven-year-old kid, even though he's an extremely smart and quick-learning one? Do you have a convincing answer to suggest for the question?
I ended up with something along the lines of “Well, the business layer - as we professional developers call it - is the nerve center of just about any software.” I hoped that such an unusual wording, topped with some emphasized pomposity of the voice, would have stopped the kid that - I thought - should be already more than happy for daring to ask and being sincerely answered. My son, however, had a different idea. So to start out, here's a brief summary of the conversation that gave my career a decisive shift towards architecture and software design. This (slightly romanticized) conversation taught me that technology is the means and not the end, and that it's primarily about business; layers come next.
Father and Son (Talking Business Layer)
The following imaginary conversation includes quotations from Cat Stevens' “Father and Son,” on his Tea for the Tillerman album, copyright 1970, Ashtar Music BV.
Dad: So you're curious about what the business layer is, right?
Son: That's right. It seems like it's quite an important thing to know even for a young man like me.
Dad: It's not time to make a change; just relax, take it easy. You're still young; that's your fault. There's so much you have to know.
Son: I want to know what the business layer is. Can you explain that to me?
Dad: How can I try to explain? Just sit down, take it slowly. You're still young; that's your fault. There's so much you have to go through.
Son: I'm curious. I want to know what a business layer is. I heard you over the phone; it seems to be quite an important thing. Maybe I should know about it, now that I'm seven.
Dad: How can I try to explain?
Son: Is it that hard to explain? Don't worry, dad. Try to use simplest words. I'll do my best to understand.
Dad: OK. So the business layer is the nerve center of any software. And software is what makes computers work.
Son: What's the business layer made of?
Dad: It's made of code and contains most of the core business logic of the system.
Son: Most or all? Is part of it elsewhere?
Dad: It contains all of the core business logic of the system.
Son: And what's the business logic?
Dad: Oh, this is an easy one! The business logic is just what you expect the computer to do.
Son: Let me see if I got it right. So the business logic is what you want to do (for example, learning) and business layer is where you do it (for example, school). Is that right?
Dad: It is. It is. Now, what about some good sleep?
Everybody agrees that the business layer is just the place where you implement the business logic. But what is the business layer made of, exactly? Answering this question gets far easier only once you know and study the user requirements and understand rules and constraints that apply to the specific context. Out of this analysis, you get essentially the vision of the business logic to implement.
Moving Away from a Technology Focus
A decade ago, the typical .NET developer was using .NET technologies (e.g., ASP.NET and Windows Forms) all day long. Building an application was primarily a matter of vaguely understanding the goals and requirements and arranging some quick prototypes that together comprised controls and scattered lines of code. All applications were essentially architected in two layers, sometimes two tiers: the client and the server.
Those claiming they were doing three-tier or multi-layer architecture were essentially isolating to a distinct layer (or even tier) any code necessary to access the database and process results. The bottom tier was the plain database with its supply of stored procedures and embedded CLR code.
There was no attention and care for things like architectural design patterns, testability, and even maintainability. Was it in the dark ages of .NET software when brains receded and yielded to marketing slogans? I think it was, or worse, the dinosaur age of .NET software. Not enough complexity was around, so focus on a sole technology was more than enough.
At the very end of the day, when it comes to business layer, it's primarily about business. Layers come next, when you turn to implementation details.
When it comes to designing the business layer, it's primarily about business. Layers come next, when you turn to implementation details.
The conversation with a 7-year old son showed, beyond any reasonable doubt, that I - the .NET guru - was unable to spot clearly and neatly the boundaries of that little messy thing called the “business layer.” At the same time, though, I was able to recognize the scope and importance of it. After more thinking, I decided that for the time being, focus on technology was more than enough for the actual business. But for the future of my career, I had to look deeper into software design and architecture. There will come a time, I said to myself - and it'll be sooner than later - when technology will be the means of understanding, and treating the business domain will be the key to success.
Focusing on the Business Domain
Many of us grew up with the architecture depicted in Figure 1. It's the canonical .NET architecture based on three layers (presentation, business, and data). In case of ASP.NET applications, the layers are typically deployed to two tiers, such as the IIS and SQL Server processes.
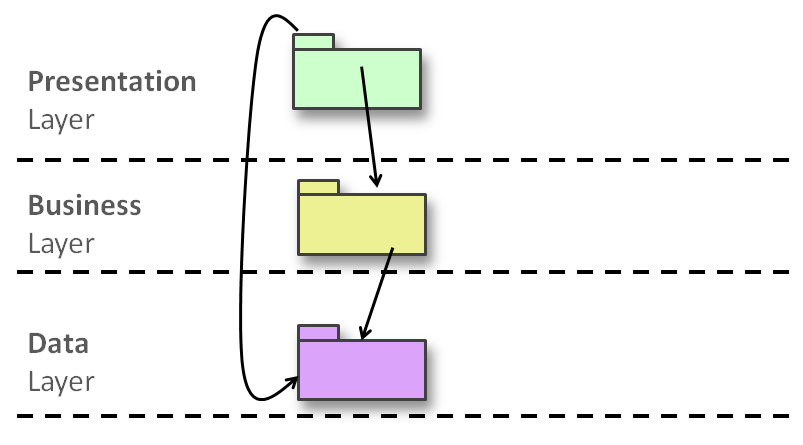
Over the last decade, I've observed a noticeable change in the industry. There was a progressive shift from data-centric three-layer architecture toward a more model-centric architecture. Another big wave of changes is coming as event-driven architecture (EDA) takes root and developers start experiencing some inherent benefits of patterns like Command/Query Responsibility Segregation (CQRS) and Event Sourcing (ES).
- EDA = Event-Driven Architecture
- CQRS = Command/Query Responsibility Segregation
- ES = Event Sourcing
- DDD = Domain-Driven Design
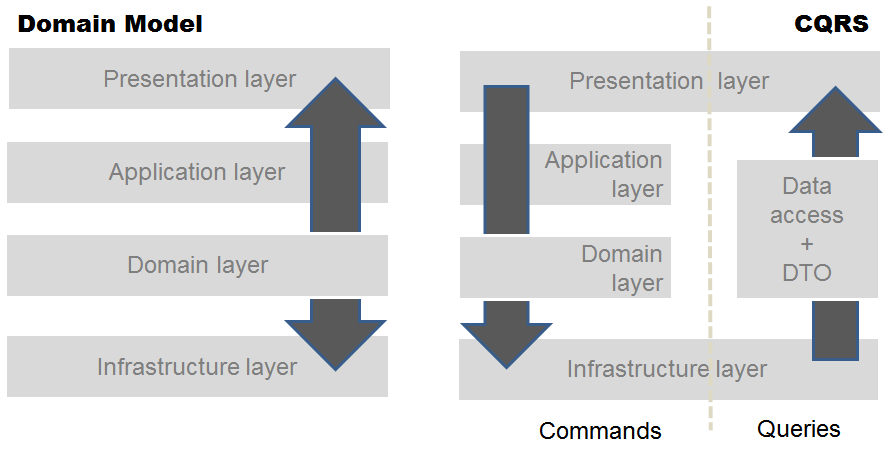
As a result, the classic business layer, canonically placed between presentation and data access, morphs into something different depending on the overall system architecture and business domain. Trying to keep the architecture abstract to the extent that it is reasonably possible, the overall layout becomes that of Figure 2.
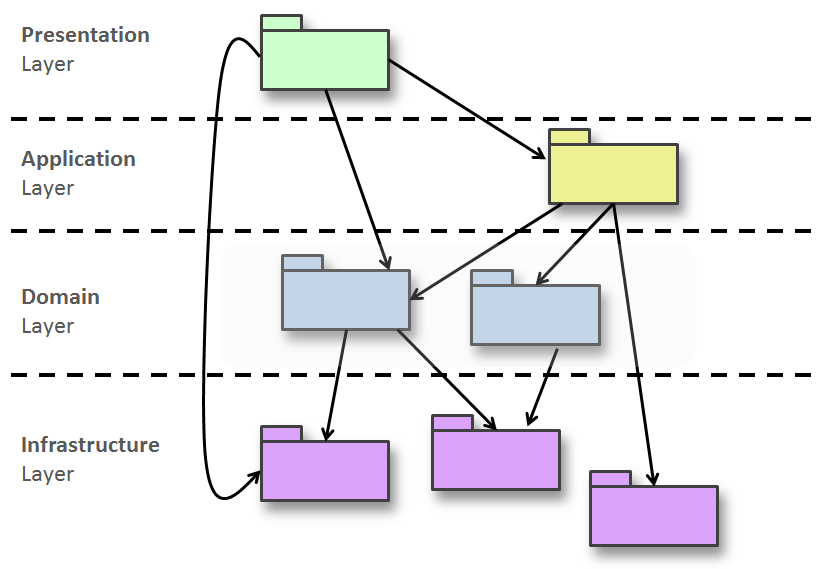
There are two major differences between the diagrams of Figure 1 and Figure 2. First, the business layer you see in Figure 1 exploded into the application and domain layers in Figure 2. Second, the data layer of Figure 1 has become the infrastructure layer of Figure 2. There's still a multi-layer architecture, but a lot has changed; and mostly in the developers' perception of business complexity and patterns to effectively implement it.
Discovering the Business Domain Inherent Architecture
A bit earlier than the time I was having that nice conversation with my son, Eric Evans published the “blue” book (“Domain-Driven Design: Tackling Complexity in the Heart of Software,” Addison-Wesley, 2003) and revealed to the world his idea of a software design approach in which the role of the business domain is central. There's no doubt that the book is a milestone in software design. However, ten years later, I'm still debating between two opinions about it.
It was a bit ahead of its time. It was timely for some 5+ years' range but it's getting outdated today.
It's still a relevant resource for today's architects, but the same author didn't completely figure out the immense power of the approach he was suggesting at the time of writing.
If it matters, I'm leaning toward the second option. The “blue” book introduces an approach to software design called domain-driven design (DDD). In the book, the author does two main things. First, he introduces the theoretical pillars of the approach; next, he comes up with a specific supporting architecture for the approach. Over the years, the supporting architecture has taken over the rest of the book and overshadowed the approach itself. Today, doing DDD mostly means creating an object-oriented model that fully describes the business domain.
In light of this, doing DDD is perceived as just having a nice-looking set of interconnected C# classes completely separated from database tables. Persistence of such graphs of objects is delegated to O/RM frameworks such as NHibernate or Entity Framework. And although NHibernate is just an object mapper (that is, it takes an object model and configuration mappings and saves it to a relational database), Entity Framework qualifies as a full-fledged framework and also provides modeling capabilities. So the Entity Framework can save an object model that you provide (this is what happens with Code First) as well as infer its own object model from a connection string and persist it.
In a nutshell, for many developers, doing DDD simply consists of creating an object model paying frantic attention to (overall minor and lightweight) implementation details such as factory methods, value classes, private setters, and object equality. Put this way, where are the benefits of DDD?
Before DDD, the typical approach to development was more or less the following:
You collect requirements and make some analysis to identify both relevant entities (e.g., customer, order, and product) and the processes to be implemented.
Armed with this understanding, you try to infer a physical data model that can support the processes. You make sure the data model is relationally consistent (primary keys, constraints, normalization, indexing) and then start building software components against tables that identify the most relevant business entities. You may also rely on database-specific features, such as stored-procedures, as a way to implement behavior while keeping the structure of the database hidden from the upper levels of code.
Finally, you strive to find a comfortable model for representing data and move it up to the presentation layer.
Frankly, this apparently obsolete approach to modeling a business domain isn't wrong and, more than everything else, it just works. Furthermore, it's a mature and consolidated practice and nearly every developer knows about it. So why should you change it for something that has a more attractive and exotic name - like DDD - but also represents a leap into the unknown?
Over the years, I took the challenge of explaining the plus-side of a domain-driven approach compared to a database-driven approach to software design many times. And often I just failed. Most of those times, however, I failed because I put the whole thing down as objects versus data readers.
Many agree that doing DDD correctly is hard; but it works very well if you succeed. And nobody mentions enough what happens if you fail. As I see things today, an object-oriented Domain Model supporting architecture for the entire stack of the application is probably a misstep. It ends up too expensive if you fail and the chances that you'll fail (for whatever reasons) are quite high. Are there enough DDD experts in the industry? Sure there are, but the point is that you become an expert only by going through failures. Are you willing to support a project failure just to help create a new team of DDD experts?
Is the entire domain-driven approach to designing a business layer deadly wrong then? Well, not exactly.
So far, I've skimmed over the pillars of DDD as described in the “blue” book, but the key to DDD is hidden there. Overall, I see two distinct parts in DDD. You always need one; and may sometimes happily ignore the other. DDD has an analytical part that sets an approach to express the top level architecture of the business domain in terms of bounded contexts. In addition, DDD has also a strategic part that relates to the definition of a supporting architecture for the identified bounded contexts. The strategic part is where the Domain Model architecture applies. Today, I'm convinced that the real added value of DDD lies in using the analytical part to identify bounded business contexts instead. The strategic part and the Domain Model pattern is just one implementation option and not even the most desirable today.
The analytical part of DDD consists of two correlated elements: the ubiquitous language and bounded contexts.
The ubiquitous language is a vocabulary shared by all parties involved in the project and thoroughly used throughout the projects, ideally in all forms of spoken and written communication. As an architect, you typically populate the vocabulary of verbs and nouns as you crunch knowledge about the domain. The ubiquitous language grabs nouns and verbs mostly from the business language and those are slightly adapted and merged with the jargon of developers (see Figure 3).
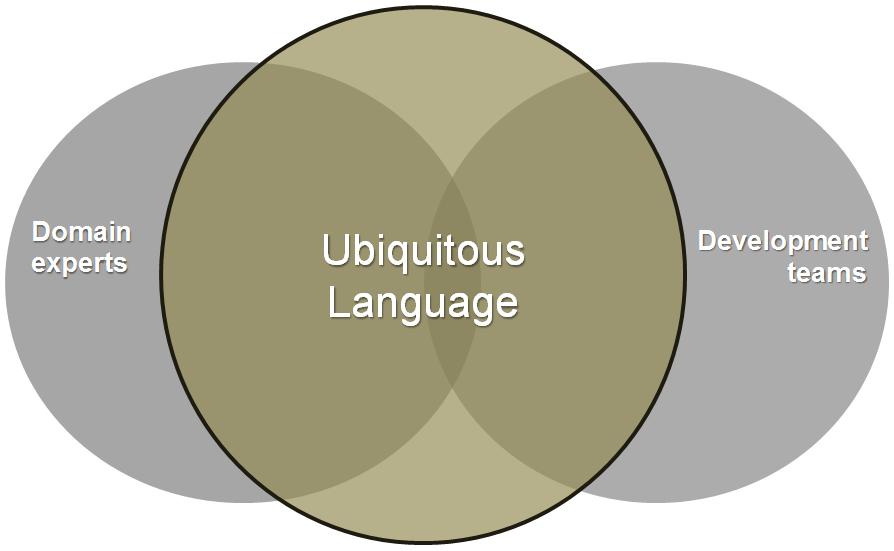
The definition of the ubiquitous language takes place as you go through requirements. The ubiquitous language is also the template that inspires the name and structure of the classes you end up writing. The ubiquitous language has the purpose of improving and speeding up the acknowledgment of requirements and simplifying communication between parties, avoiding misunderstandings, assumptions, and translations from one jargon to another.
Initially, there's just one ubiquitous language and a single business domain to understand and model. As you understand requirements and explore the domain further, you may realize that there's some overlapping between nouns and verbs and find out that they are used in different areas of the domain with a different meaning. This may take you to see the original domain split into multiple subdomains.
The ubiquitous language has the purpose of avoiding misunderstandings, assumptions, and translations from one jargon to another.
Bounded context, instead, is the term that DDD uses to refer to areas of the domain that are better treated independently because they can be expressed via their own ubiquitous language. Put another way, you recognize a new bounded context when the ubiquitous language changes and a few terms start getting a different meaning. Out of a DDD analysis, any business domain is made of contexts and each context is shaped by logical contours. The primary responsibility of a software architect is identifying business contexts in a domain and defining their logical contours.
It's relatively easy to split a business domain into a variety of subdomains, each representing a bounded context to render with software. But is it splitting or is it partitioning?
Sometimes it's relatively easy to split a business domain into a variety of subdomains, each representing a bounded context to render with software. But is it splitting or is it partitioning? That would make a huge difference. Frankly, in the real world, you hardly see business domains that can be easily partitioned in child domains with nearly no overlapping of functions and concepts. So, in the end, it's more splitting than partitioning. The problem of splitting a business domain is marking the boundaries of each context, identifying areas of overlapping, and deciding how to handle those. As mentioned, the first concrete clue of a new subdomain is when you find a new term used to express a known concept or when the same term is found to have a second meaning. This indicates some overlapping between subdomains (see Figure 4).
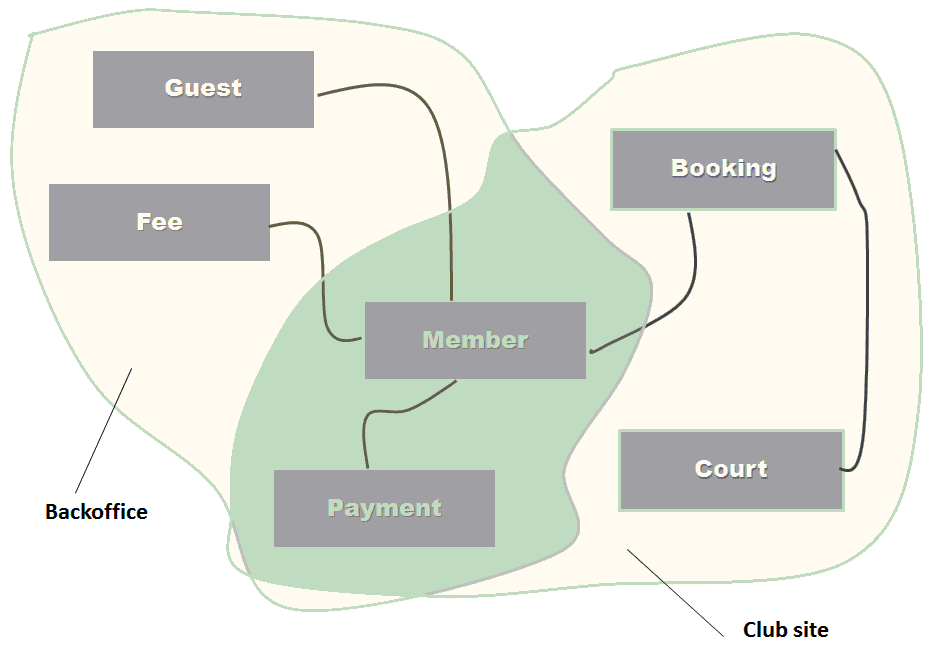
Figure 4 presents a sample diagram of entities in a domain (a sporting club). The business domain is made of a subdomain (let's call it the Club site) that offers booking of courts. Booking courts requires entities like members and payments. The backoffice is a distinct but related subdomain that also handles entities like members and their payments. So both subdomains deal with members and payments even though each has a different vision (read: class prototype) of them. By having distinct context for backoffice and Club site, you can still use the appropriate language and avoid bloated classes to cope with different contexts.
Once you have identified bounded contexts (i.e., a concept for which the term “sub-system” is an appropriate synonym), you draw relationships between them. This step is known as context mapping. Context mapping builds a high-level view of the domain from the perspective of a software architect. It shows subdomains and their relationships and helps making strategic decisions about implementation.
The true value of DDD is in defining two universal tools and a universal methodology to design software for a specific business domain. Building the ubiquitous language helps to make sense of requirements and leads to crunching solid knowledge about the processes and mechanics of the domain. Mapping bounded contexts splits complexity across multiple subsystems, each of which is then designed independently. Note that “independently” here means that each bounded context is allowed to have its own architecture and set of technologies. For example, one bounded context can be a full Domain Model implementation, while another one can be a plain simple two-tier CRUD system. Yet another can be a WordPress component or perhaps a Web API set of endpoints.
This way of designing is common sense and universal; but DDD adds a theoretical foundation to it and, more importantly, it defines a set of usable tools and guidelines. The lesson learned from the “blue” book is that there's no need to find a single universal architecture that works for everybody. Building an object model that covers all possible aspects of the domain is (both in reading and writing), while not impossible, quite hard. It's much more effective to stop at bounded contexts. And bounded contexts were formalized in DDD (but not advertised much) since day one.
From Data to Tasks
We write software to mimic aspects and processes of the real world. Why focus on data models then? Isn't focusing on tasks more appropriate? As obvious as it may sound, focusing on tasks also simplifies design. Analyzed, each task has actors and data being moved around. The intended revolutionary approach of DDD to the business layer and application design is shifting in focus from the data model to a model that best represents the actual processes. As an example, consider the checkout process in a typical e-commerce application.
When the user completes an order and pushes the Submit button, an order record is created somewhere - likely within some relational database. If your design focuses on data entities being used, where would you store the behavior required to prepare entities? In a Web scenario, the Submit button will likely post an HTML form to some ASP.NET backend.
The data being transferred is a collection of data items - not certainly an instance of some Order class. Before the order can be saved, a number of steps occur along the way: validating the list of ordered items, checking the payment history of the customer, syncing up with the shipment company, dealing with the bank gateway for online payment, emailing the customer in case of issues, and interacting with the internal invoicing system, for instance. Then comes the time of creating a new order line in some database.
Where would you place all this code? In a data-centric vision of the world, you'd probably have code like this:
OrderModule.Create( /* data from HTML form */);
In a task-based scenario, you'd have something like this:
CheckoutService.ProcessOrder(
/* data from HTML form */
);
Is that a huge difference?
In the first place, it is a matter of language. The second form reflects the actual language of the business - the aforementioned ubiquitous language. Don't underestimate the impact of an inaccurate ubiquitous language. If you happen to read the code of an existing and sufficiently complex application using fancy or misleading names for entities and classes, well, it would drive you crazy in a matter of minutes and you end up wondering who the idiot was who wrote that.
Secondly, an OrderModule component (or whatever name you choose for it) seems to reflect a vision of the domain in which the order and the action of creating it is predominant. It reflects a database-centric vision.
Again, is that huge difference?
Database-centric versus task-based can be an endless game with no winner. Choosing the task-based approach over the database-centric approach, however, does help to create an application more resilient to changes and more quickly adherent to requirements. In the end, in fact, nearly all applications end up in production with mutual satisfaction. The question is, at what cost? A design approach that helps minimize the wrinkles between requirements and acknowledgement is particularly valuable. To end users, software applications are tools to perform tasks. So why would a database-centric approach be preferable over a task-based approach?
Like it or not, task-based design is taking root for the simple reason that it helps make things simpler to design and implement. Speaking of task-based analysis and design, CQRS comes up.
CQRS is a natural fit in a system dependent on collaboration. However, the benefits of command/query separation can apply to nearly all systems.
As mentioned, CQRS is an emerging approach to designing software systems. For what I can see, it's the new standard that goes beyond DDD while making it overall simpler and more affordable for everyone. CQRS is founded on a surprisingly simple idea. Most of the difficulties that early adopters of DDD faced were designing in a single model that could take care of all aspects of the domain. Generally speaking, any action performed on a software system is a query or command. In this context, a query is an operation that doesn't alter in any way the state of the system and just returns data. The command, on the other hand, does alter the state of the system and doesn't return data, except perhaps for a status code or an acknowledgment message.
Logically speaking, queries and commands are neatly separated. However, the logical separation that exists between queries and commands doesn't show up clearly if the two groups of actions are forced to use the same domain model. On the other hand, choosing to break any system into two distinct stacks proved to be an excellent (and quite obvious) way to do the same things in a simpler way. I estimate that calling Q and C the complexity of the query and command stack of a system, the resulting complexity of a Domain Model architecture is QxC; it's Q+C in a CQRS scenario.
By choosing CQRS, you're inevitably forced to reason in terms of actions - queries to perform and commands to execute. This apparently minor point is like the classic grain of sand that blocks a sophisticated gear mechanism - you remove it and it all magically works seamlessly. When planning code for a query or command action, you must know very well what comes in, what comes out and what happens along the way. This instantly translates to a better and deeper knowledge of the domain and user processes. That, in turn, significantly reduces long-term misunderstandings that are to be fixed when the system is in a dangerously advanced development phase. And the chain of benefits - the virtuous circle of CQRS - continues.
Either CRUD Doesn't Exist or Everything is CRUD
The business layer has been tightly bound to the idea of CRUD (Create/Read/Update/Delete) systems for a long time. “All I need - many developers said - is a plain simple CRUD system. Why should I do anything different from designing a SQL Server database and some forms around it?” As mentioned, when it comes to the business layer, it's all about the actual business. So is your business simple enough that all you need to do is add and delete records from a bunch of database tables? If so, that's great. By saying so, though, you implicitly admit that most other software is far more complex. If you find this scenario way too simple, you're implicitly admitting that you call it CRUD because all it does is essentially perform four fundamental operations over a bunch of primary entities.
In the previous sentence, “essentially” seems to indicate that more operations may be required and that even basic CRUD operations may not be that straight-forward to perform. Also, “primary entities” leaves the door open to entities of different levels of complexity and nesting. Note that the major difficulty of coming up with a full-fledged object-oriented domain model is merely the boundary of identified entities and their relationships. This concept is called “aggregate” in the DDD jargon.
At the end of the day, pure CRUD systems exist only in some conference demos aimed at illustrating how quick and codeless a certain technology can be. The real world is different just because it's “real.” The challenge today is coming up with a new software architecture that's as pervasive as classic CRUD and helps deal with complexity better. Compared to the software we were writing in the past decade, modern software is intrinsically more complex, and part of its increased complexity is due to the needs of supporting sophisticated and varying presentation layers.
Distinguishing CRUD systems from the remainder of software systems seems more pointless to me every day. Most systems are CRUD systems to some extent; and all CRUD systems include a bit of business logic (or at least, validation logic). We should manage to find a better solution for all systems.
CQRS is Today's CRUD
CQRS is not a comprehensive approach to the design of a software system as, for example, is the case with DDD. CQRS is a pattern that guides you in architecting a specific bounded context of a possibly larger system. Performing a DDD analysis based on a ubiquitous language and aimed at identifying bounded contexts remains a recommended preliminary step. Next, CQRS becomes a valid alternative to Domain Model, CRUD, and other supporting architectures for the implementation of a particular bounded context.
Is CQRS specific to a particular class of applications? Or is it recommended for just any application?
Honestly, I don't see significant downsides around CQRS. It all depends, in the end, on what you mean exactly by using CQRS. In this article, I defined CQRS as a pattern suggesting that you have two distinct layers: one filled with the model and services necessary for reading, and one with the model and services for commands. What a model is - whether it's an object model, a library of functions, or a collection of data-transfer objects - ultimately, it's an implementation detail.
With this definition in place, nearly any system can benefit from CQRS, and coding CQRS doesn't require doing things in a different way. Neither does it mean learning new and scary things. This marks a huge difference in the Domain Model pattern. The essence of CQRS compared to the Domain Model pattern is summarized in Figure 5.
If you search around for CQRS, you will likely run into articles and posts - fairly old references actually - that present CQRS as a pattern ideal for collaborative systems. A collaborative system is quite a sophisticated system in which the underlying data can change at any time from the effect of the current user, concurrent users connected through various front ends, and even back-end software. In a collaborative system, users compete for the same resources, and this means that whatever data you get can be stale in the same moment that it's read or even long before it's displayed. One of the reasons for this continuous change is that the business logic is particularly complex and involves multiple modules that sometimes need to be loaded dynamically. In this scenario, separation between read and write stacks comes to the rescue. With a CQRS architecture, the logic can be expressed through single commands that result in distinct, individual components that are much easier to evolve, replace, and fix. In addition, these commands can be queued and concatenated through events, if necessary.
Many seem to think that outside the realm of collaborative systems, the power of CQRS diminishes significantly. On the contrary, the power of CQRS really shines in collaborative systems because it lets you address complexity and competing resources in a much smoother and overall simpler way. There's more to it than catches the eye, I think.
As I see things, CQRS can sufficiently pay your architecture bills even in simpler scenarios, where the plain separation between query and command stacks leads to simplified design and dramatically reduces the risk of design errors. You don't need to have super-skilled teams of developers to do CQRS. Quite the opposite: Using CQRS enables nearly any team to do a good job in terms of scalability and cleanliness of the design. Let's review ways to reshape the business layer using CQRS.
The Business Layer at the Time of CQRS
Most systems out there can be summarized as CRUD systems with some business logic. Applying CQRS to such a CRUD system entails using the Transaction Script (TS) pattern in the implementation of the command stack. TS is a simple programming approach according to which you partition the back end of the system - overall, the business logic - in a collection of methods defined in a few container classes. Each method essentially takes care of one command and provides a full end-to-end implementation for it. The method, therefore, takes care of processing input data, invoking local components or services in another bounded context, and writing to the database. All these steps take place in a single logical transaction, which is where the name of the pattern comes from. Figure 6 provides a quick at-a-glance view of the TS pattern.
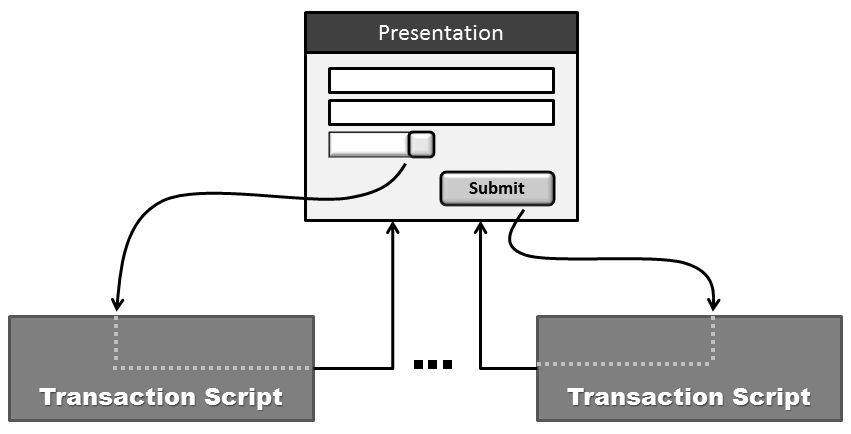
As Martin Fowler said in his book “Patterns of Enterprise Application Architecture,” the glory of TS is in the simplicity that makes it a natural fit for applications with a small amount of logic. The major benefit of the TS pattern is that there's only minor overhead for development teams in terms of learning and performance. Is this different from any other approach based on direct ADO.NET queries and DataSets? Let's just call TS+CQRS a revised version of it.
Some of the ideas in this article are inspired by my recently released book “Microsoft .NET: Architecting Applications for the Enterprise”, 2nd edition, Microsoft Press, 2014.
Once you know the connection string to the database to access, you create an Entity Framework wrapper in the form of an EDMX designer file in Microsoft Visual Studio. If you have the database in mind, or if you feel more comfortable designing the database first, you can still do business (layer) as-usual, except that you code commands and queries separately in distinct classes and stacks.
Running the Entity Framework designer on the specified connection string infers an object model out of the database tables and relationships. Because it comes from Entity Framework, the object model is essentially anemic. However, the C# mechanism of partial classes enables you to add behavior to classes, thus adding a taste of object orientation and domain modeling to the results.
Arranging commands on top of this object model is easy for most developers, and it's effective and reliable. Expert developers can work very quickly with this approach, and junior developers can learn from it just as quickly. Arranging queries - possibly just LINQ queries - is easy for everybody regardless of their skills.
As an architect, you might wonder what the added value of CQRS is in relatively simple systems with only a limited amount of business logic. Well, you can pass each developer an amount of work that is commensurate to that developer's actual skills. You still have two distinct stacks to be optimized and fixed independently, or even rewritten from scratch if necessary. In a word, an expert architect has a far better chance to take on the project comfortably, even with only junior developers on the team.
Figure 7 depicts a more sophisticated CQRS architecture in which the business logic of the command stack is expressed through commands and events. The query stack may read directly from the command database or from a sort of cache, if that helps in terms of performance and database costs.
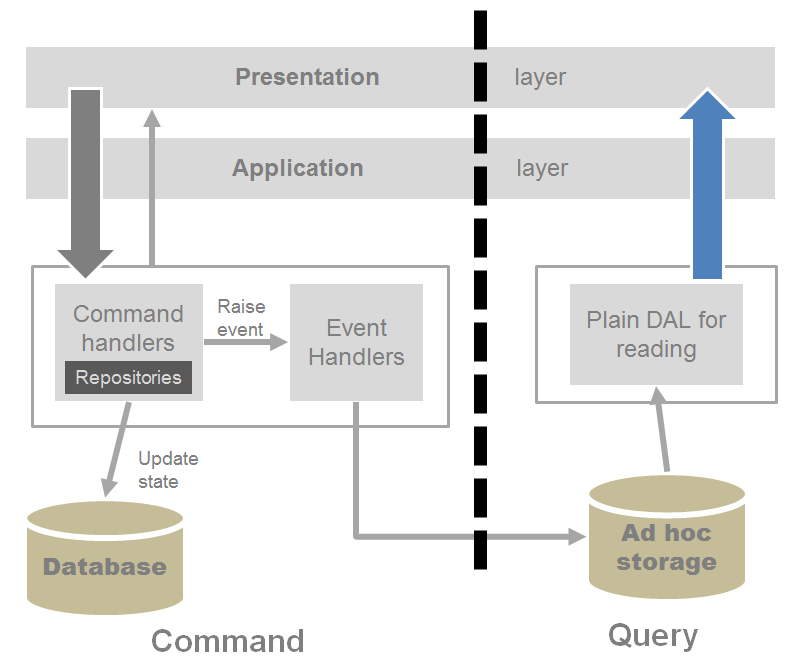
In the architecture of Figure 7, the command stack may rely on a full Domain Model as well as a simpler set of TS classes. If a Domain Model is used, it only contains entities and relationships related to the execution of commands. It ends up being far simpler, as it doesn't have to take care of data structure for queries. This removes a lot of one-to-many relationships from the model.
On the query side, you don't strictly need a read domain model. All you need to do is execute queries, and you can do that directly using LINQ-to-Entities or LINQ in-memory collections. You bring the LINQ IQueryable object up to the application layer and project the query to the data you need to serve the presentation layer in the particular use-case you're considering.
The Mythical Business Layer
A lot of words have been said trying to define what the business layer is, or is supposed to be. Overall, I believe that everybody has a clear idea of what the business layer is. This is summarized in the sentence: “It's where you code the business logic of the system,” The problem is that “business logic” is no longer an atomic concept. Today, you need to split it into at least two types of distinct “logic:” application logic and domain logic. What you accept as “application logic” today has been a gray area for many years. This was at the foundation of my inability to quickly formalize the idea of business layer to my son more than ten years ago.
Application logic is well defined by saying that it's the layer that implements the workflow behind each use-case you have in the presentation. The workflow is then made of several steps that involve both external services (e.g., weather forecasts) and domain services (pieces of business specific logic, such as booking a court or inviting a guest).
This split is key to making the business layer a bit less mythical but more - much more - concrete. Once you make this (evolutionary) step, the final step is finding a way to implement the domain logic. It's mostly a matter of having services that use data, which can be a sophisticated object model or a plain collection of data-transfer objects. Details depend on the pattern you choose. My best recommendation today is distinct command/query separation and TS or Domain Model for the command stack. The query stack, instead, is simple queries against some (No)SQL database.
Remember the James Bond's movie “License to Kill”? At some point, a man called Sanchez was about to be killed by the canonical “bad guy.” The killer gently said “I want you to know this is nothing personal. It's purely business! See you in hell, Mr. Sanchez!”
Similarly, I want you know the way you write the business layer is nothing personal, but it's purely a matter of serving the business needs. See you in the next software hell!
