


While sleepless the other night, I was channel surfing and ran across a rerun of the 1968 science fiction classic “2001: A Space Odyssey.”
If you haven't seen this movie, it's definitely a must see. HAL, one of the main characters of the movie, is a slightly psychotic speech-enabled super computer. HAL is responsible for steering the Discovery spacecraft on its ill-fated Jupiter mission. As I watched the movie I was completely amazed at HAL's abilities. HAL handled press interviews, played a wicked game of chess, has varied opinions on art, controls life support, and can read lips. Not to completely destroy the movie if you haven't seen it, but I have to say that I am grateful that most of the movie's predictions aren't true. However, like the HAL of 1968, speech-enabled applications have become a core requirement for both corporate and commercial developers. In this article, I'll help you explore the Microsoft Speech Platform that comprises the Speech Application Software Development Kit (SASDK) and Microsoft Speech Server 2004. I'll also show you how you can use these technologies with Visual Studio 2003 to both build and deploy speech-enabled applications.
The SASDK is the core component of the Microsoft Speech platform that enables developers to create and debug speech-based applications for telephones, mobile devices, and desktop PCs.
The name HAL was derived from a combination of the words “heuristic” and “algorithmic.” These are considered the two main processes involved in human learning. These were important characteristics for early speech developers as well. Initially, speech applications were targeted at a “say anything” programming mentality. The result was a very specialized type of system-level programmer. Among other things, they studied natural speech and language heuristics to develop a set of unique algorithms for their applications. Interestingly, they were actually part application developer, language expert, and hardware engineers. The good news is that the mainstreaming of speech-based technology has enabled us, as mere mortal ASP.NET developers, to leverage this type of technology. The familiar combination of Visual Studio 2003 coupled with a free add-on kit called the Speech Application Software Development Kit (SASDK) allows your Web-based application to include speech functionality. It is the integration of these familiar toolsets into a server-based product called Microsoft Speech Server 2004 that completes the server-side solution and brings speech to the mainstream Windows platform.
The Architecture of Speech-Enabled Applications
The SASDK is the core component of the Microsoft Speech platform that enables Web developers to create and debug speech-based applications for telephones, mobile devices, and desktop PCs. The SASDK includes a set of samples, documentation, and debugging utilities that are important for developing speech applications. This includes a set of speech authoring tools I will cover later that are directly integrated into the Visual Studio 2003 environment. Finally, the SASDK installs a new project template (Figure 1) that serves as the starting point for any speech application. Typically, the lifecycle of developing a speech application starts with the tools available within the SASDK and Visual Studio 2003, and once completed the application in then deployed to the Microsoft Speech Server 2004 (MSS).
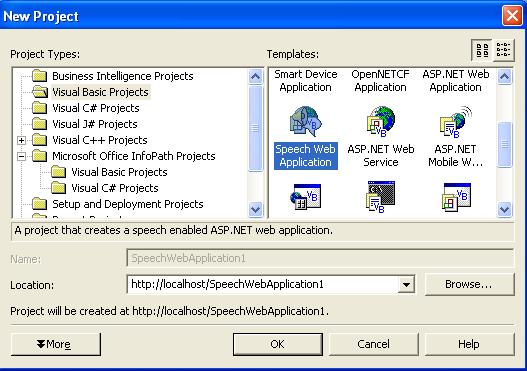
One of the main design goals of both the MSS and SASDK was to leverage existing standards and ensure industry compliance to make speech a natural extension of any Web-based application. In addition to the basics of XML, HTML, and JavaScript, there are several speech-related standards as shown in Table 1.
Defining the Application
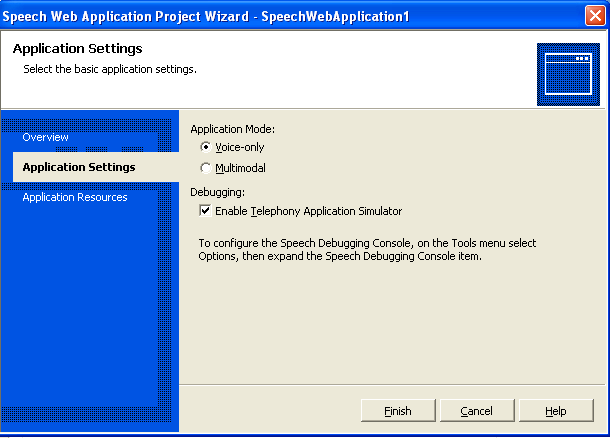
Both the SASDK and Microsoft Speech Server are designed to develop and support two distinct types of speech-based applications-voice only and multimodal. By default the developer selects the application type when they create a new project as shown in Figure 2. The role of the SASDK is to provide a developer-based infrastructure to support both the development and debugging of either type on a local machine. On the other hand, the MSS is designed to provide a production-level server-side environment for deployed speech-based applications. Figure 3 shows a sample schematic of a production environment that includes Microsoft Speech Server.
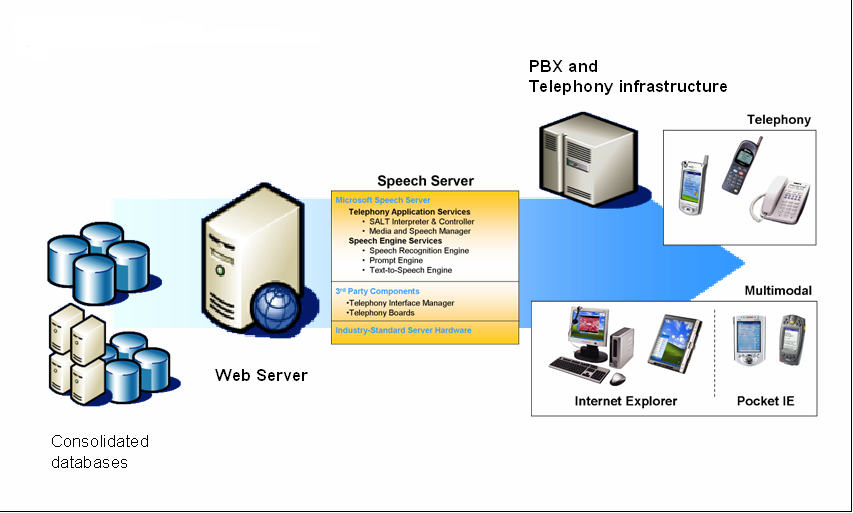
Voice-only applications are designed to never expose a visible Web interface to end users. This type of speech application includes both traditional voice only applications and touchtone or Dual Tone Multi-Frequency (DTMF) applications. In either case, all interaction with the application is done by either voice only or keypad presses. The result is a menu option or selection based on the user's response. Once deployed, the Microsoft Speech Server includes two major components that are designed to support these types of applications in a production environment. The Telephony Application Service (TAS) is responsible for providing a voice only browser or SALT interpreter which is used to process the SALT markup generated by the ASP.NET speech-enabled Web application. Also, the Speech Engine Services (SES) that provides the speech recognition engine also handles the retrieval of the output generated by the application. Finally, the Telephony Interface Manager (TIM) component provides the bridge between the telephony board hardware which is connected to both the network and the TAS.
Both the SASDK and Microsoft Speech Server are designed to develop and support two distinct types of speech based applications-voice only and multimodal.
Multimodal applications, on the other hand, are designed to combine speech input and output with a Web-based graphical user interface. In a traditional Web-based GUI, the user directs the system through a combination of selections and commands. Each action is translated into a simple sentence that the system can execute. Fundamentally, each sentence contains verbs that act on a direct object. The selection of the mouse defines the direct object of a command, while the menu selection describes the action to perform. For example, by selecting a document and choosing print, the user is telling the computer to “Print this document.” In multimodal systems, speech and mouse input are combined to form more complex commands. For example, by selecting a document and simultaneously saying “Print five of this” the user successfully collapses several simple sentences into a single Click command. Obviously this type of application is best suited for devices that support both speech and ASP.NET. However, for mobile devices like PDAs this is particularly well-suited because conventional keyboard input is difficult. For developers, a multimodal application combines ASP.NET and speech controls with server-side extensions like SALT for application delivery. Once an application is deployed to Microsoft Speech Server it is responsible for providing output markup that includes SALT, HTML, JavaScript, and XML to the client and the speech services needed for voice interaction.
Building Speech Applications
Like any Web-based application, speech applications have two major components-a Web browser component and server component. Realistically, the device that consumes the application will ultimately determine the physical location of the Speech Services engine. For example, a telephone or DTMF application will natively take advantage of the server-side features of Microsoft Speech Server. However, a desktop Web application will leverage the markup returned by MSS in conjunction with desktop recognition software and the speech add-ins for Microsoft Internet Explorer.
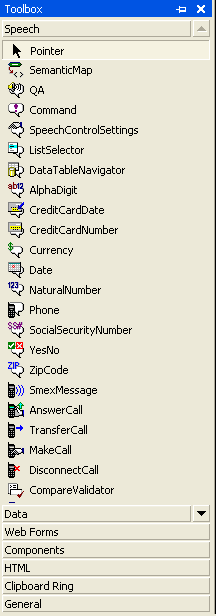
In addition to the default project template, the SASDK also installs a set of speech-enabled ASP.NET controls. By default these controls are added to the Visual Studio toolbox as shown in Figure 4. Fundamentally, these controls operate identically to the standard set of ASP.NET Web controls except that during the server-side rendering phase of a Web page containing a speech control, the output document contains SALT, SSDN, and SRGD in addition to the standard HTML and JavaScript. The document returned to the speech-enabled client is first parsed and then any additional grammar files specified in the returned markup are downloaded. Additionally, if the Speech Services engine is local, prompts or pre-recorded text are also downloaded. Finally, both the SALT client and Web browser invoke the series of <prompt> and <listen> elements specified by the markup. Any additional client-side elements are invoked by calling the client-side start() function.
Once started, the Speech Services engine listens for input from the user when a <listen> element is invoked. Once it receives the response audio or utterances it compares it's analysis of the audio stream to what is stored in the grammar file, looking for a matching pattern. If the recognizer finds a match a special type of XML document is returned. This document contains markup called Semantic Markup Language (SML) and is used by the client as the interpretation of what the user said. The client then uses this document to determine what to do next. For example, execute a <prompt> or <listen> element. The cycle repeats itself until the application is done or the session ends.
All ASP.NET speech controls are implemented in the framework namespace Microsoft.Speech.Web.UI. Within the namespace, these controls are categorized by their functions. By default, these categories are basic, dialog, application controls, and Call management controls. Call Management controls are an abstraction of the Computer Supported Telecommunications Applications (CSTA) messages you'll use in your application.
Like any other ASP.NET Web control, the speech controls are designed to provide a high level abstraction on top of the lower-level XML and script emitted during run time. Also, to make the implementation of these controls easier, each control provides a set of property builders as shown in Figure 5.
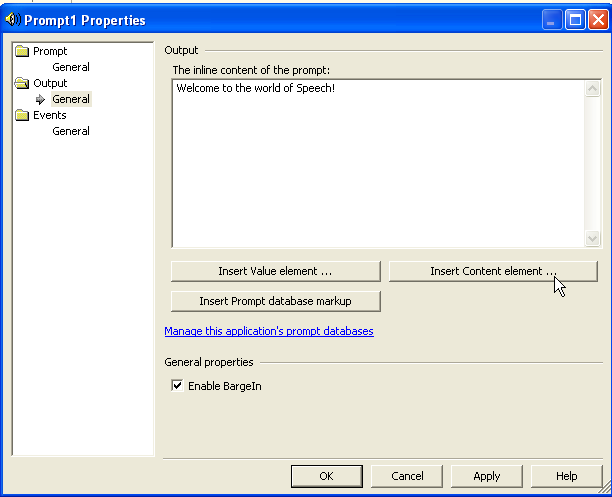
The Basic Speech Controls
The basic speech controls, which include Prompt and Listen, are designed to create and manipulate the SALT hierarchy of elements. These controls provide server-side functionality that is identical to the elements invoked during run time on the client. The Prompt control is designed to specify the content of the audio output. The Listen controls perform recognition, post processing, recording, and configuration of the speech recognizer. Ideally, the Basic controls are primarily designed for tap- and talk-based client devices and applications designed to confirm responses and manage application flow through a GUI.
The basic speech controls are designed exclusively to be called by client-side script. Examining the “Hello World” example in Listing 1, you will notice that once the user presses the Web page button this then calls the OnClick client-side event. This event invokes the Start method of the underlying prompt or exposed SALT element. The event processing for the basic speech controls is identical to features of SALT. Fundamentally, these features are based on the system's ability to recognize user input. The concept of recognition or “reco” is used by SALT to describe the speech input resources and provides event management in cases where valid recognition isn't returned. For example, you create specific events such as “reco” and “noreco” and then assign the name of these procedures to control properties such as OnClientReco and OnClientNoReco. When the browser detects one of these events, it calls the assigned procedure. The procedure is then able to extract information about the event directly from the event object.
Listing 1: Welcome to speech application
<%@ Page Language="vb" AutoEventWireup="false" Codebehind="Default.aspx.vb" Inherits="SpeechWebApplication3._Default"%>
<%@ Register TagPrefix="speech" Namespace="Microsoft.Speech.Web.UI" Assembly="Microsoft.Speech.Web, Version=1.0.3200.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" %>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<HTML>
<HEAD>
<title>Default</title>
<meta name="GENERATOR" content="Microsoft Visual Studio .NET 7.1">
<meta name="CODE_LANGUAGE" content="Visual Basic .NET 7.1">
<meta name="vs_defaultClientScript" content="JavaScript">
<meta name="vs_targetSchema" content="http://schemas.microsoft.com/intellisense/ie5";>
</HEAD>
<body MS_POSITIONING="GridLayout" xmlns:speech="http://schemas.microsoft.com/speech/WebControls";>
<form id="Form1" method="post" runat="server">
<script >
function PlayWelcomePrompt() {
Prompt1.Start();
}
</script>
<INPUT type="button" value="<Play>" onclick="PlayWelcomePrompt()">
<speech:Prompt id="Prompt1" runat="server">
<InlineContent>Welcome to the world of speech!</InlineContent>
</speech:Prompt>
</form>
</body>
</HTML>
The Listen control is a server-side representation of the SALT List element. The Listen element specifies possible speech inputs and provides control of the speech recognition process. By default, only one Listen element can be active at a time. However, a Web page can have more than one Listen control and each control can be used more than once.
Listing 2 represents the HTML markup when a Listen control is added to a Web page. As you can see, the main elements of the Listen control are grammars. Grammars are used to direct speech input to a particular recognition engine. Once the audio is recognized, the resulting text is converted and placed into an HTML output.
Listing 2: Markup representing a Listen control
<speech:listen id="AskDateListen"
runat="server"
AutoPostBack="true"
OnReco="SetCalendar"
EndSilence="1000"
InitialTimeout="2000"
MaxTimeout="15000">
<Grammars>
<speech:Grammar Src="Grammars/DateGrammar.grxml" ID="Grammar2"></speech:Grammar>
</Grammars>
</speech:listen>
Dialog Speech Controls
The dialog speech controls, which include the QA, Command, and Semantic items, are designed to build questions, answers, statements, and digressions for an application. Programmatically, these controls are called through the script element, RunSpeech, which manages both the execution and state of these controls. RunSpeech is a client-side JavaScript object that provides the flow control for voice-only applications. Sometimes referred to as the dialog manager, it is responsible for activating the dialog speech controls on a page in the correct order. RunSpeech activates a Dialog speech control using the following steps:
The QA control within the Microsoft.Speech.Web.UI.QA namespace is used to ask questions and obtain responses from application users. It can be used as either a standalone prompt statement or can supply answers for multiple questions without having to ask them. Listing 3 shows an example of how you can mark up this control.
Listing 3: Asking questions and obtaining responses with the QA control
<speech:QA id="SubType" runat="server">
<Prompt InlinePrompt="What type of submarine sandwich would you like?"/>
<Answers>
<speech:Answer SemanticItem="sisubType" ID="subTypeAnswer" XpathTrigger="./subType"/>
</Answers>
<Reco InitialTimeout="2000" BabbleTimeout="15000" EndSilence="1000" MaxTimeout="30000">
<Grammars>
<speech:Grammar Src="subGrammar.grxml#TypeRule"/>
</Grammars>
</Reco>
</speech:QA>
The Command control contained in the Microsoft.Speech.Web.UI.Command namespace enables developers to add out-of-context phrases or dialogue digressions. These are the statements that occur during conversations that don't seem to make sense for the given dialog. For example, allowing an application user to say “help” at any point. The following is an example of how you can apply this globally to a speech application.
<speech:command id="HelpCmd" runat="server" scope="subType" type="Help" xpathtrigger="/SML/Command/Help">
<grammar id="GlobalHelpCmd" runat="server" src="GlobalCommands.grxml" />
</speech:command>
The SemanticMap and SemanticItem controls track the answers and overall state management of the dialogue. You use Semantic items to store elements of contextual information gathered from a user. While the semantic map simply provides a container for multiple semantic items, each SemanticItem maintains its own state. For example, these include empty, confirmed, or awaiting confirmation. You'll use the SemanticMap to group the SemanticItem controls together. Keep in mind that while the QA control manages the overall semantics of invoking recognition, the storage of the recognized value is decoupled from the control. This simplifies state management by enabling the concept of centralized application state storage. Additionally, this makes it very easy to implement mixed-initiative dialog in your application. In a mixed-initiative dialog, both the user and the system are directing the dialog. For example, the markup for these controls would look like the following.
<speech:semanticmap id="TheSemanticMap" runat="server">
<speech:semanticitem id="siSubSize" runat="server" />
<speech:semanticitem id="siSubType" runat="server"/>
<speech:semanticitem id="siFootLong" runat="server" />
</speech:semanticmap>
Prompt Authoring
Prompts are such an important part of any application because they serve as the voice and interaction point with users. Basically, they act as the main interface for a dialog-driven application. As you begin to build a speech application you will quickly notice that the synthesized voice prompts sound a bit mechanical; definitely not like the smooth slightly British tone of HAL in “2001.” This is because, by default, unless otherwise specified the local text to speech engine will synthesize all prompt interaction. Prompts should be as flexible as any portion of the entire application. Just as you should invest time in creating a well-designed Web page, so should you spend time on designing a clean sounding dynamic prompt system for application users to interact with. As with any application, the goal is to quickly prototype the proof of concept and usability testing. The extensibility of the speech environment makes it easy to have a parallel development track occurring of the dialog and prompt recording.
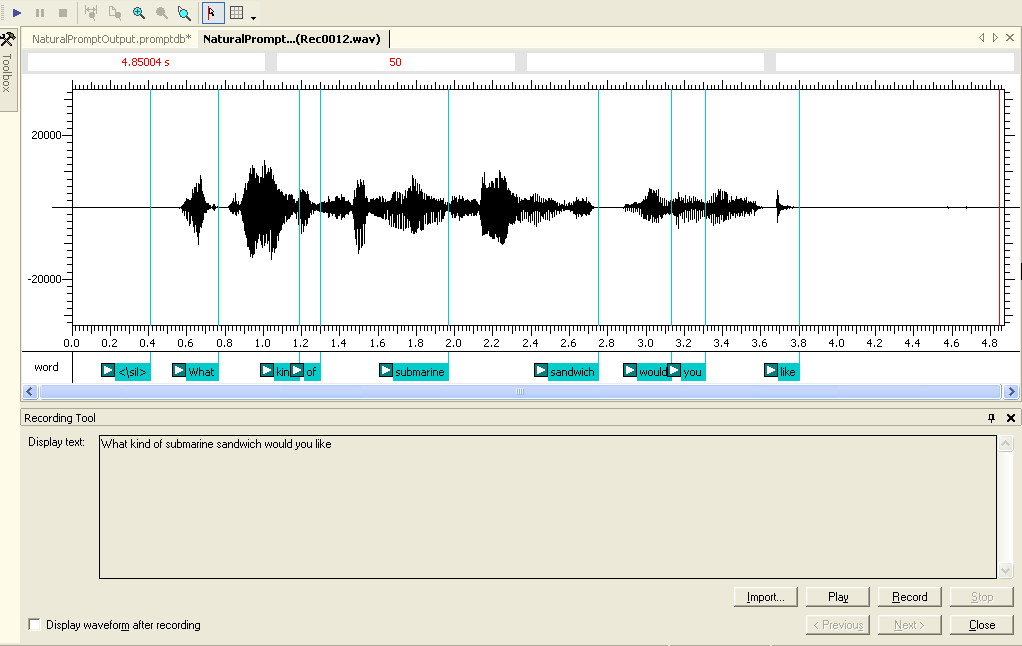
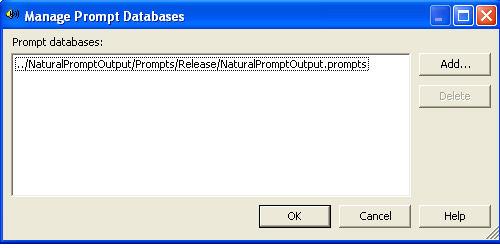
The Prompt database is the repository of recorded prompts for an application. It is compiled and downloaded to the telephony browser during run time. Before the speech engine plays any type of prompt, it queries the database and if a match is found, it plays the recoding instead of using the synthesized voice. Within Visual Studio the Prompt Project is used to store these recordings and is available within the new project dialog as shown in Figure 6. The Prompt Project contains a single prompt database with a .promptdb extension. By default, Prompt databases can be shared across multiple applications and mixed together. In practice it's actually a good idea to use separate prompt databases across a single application to both reduce size and make it more manageable. The database can contain wave recording either directly recorded or imported from external files.
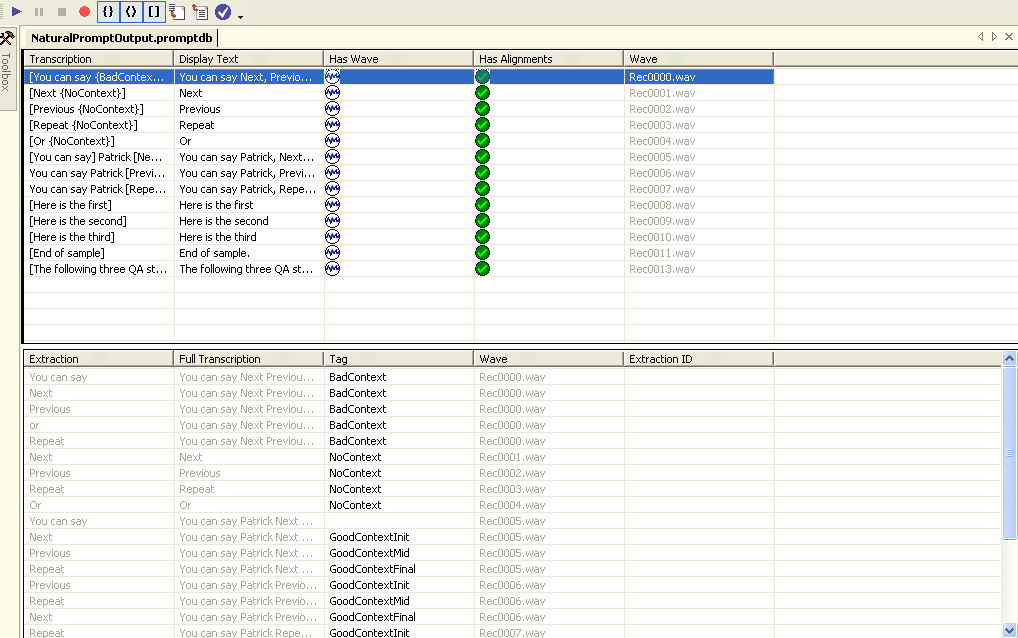
You can edit the prompts database through Visual Studio's Prompt Editor as shown in Figure 7. This window is divided into a Transcription and Extraction window. The Transcription window (top) is used to identify an individual recording and its properties. These include playback properties including volume, quality, and wave format. More importantly, you use the Transcription window to define the text representation of the wave file content. The bottom portion of the Prompt Editor contains the Extraction window. This identifies one or more consecutive speech alignments of a transcription. Essentially, extractions constitute the smallest individual element or words within a transcription that a system can use as part of an individual prompt.
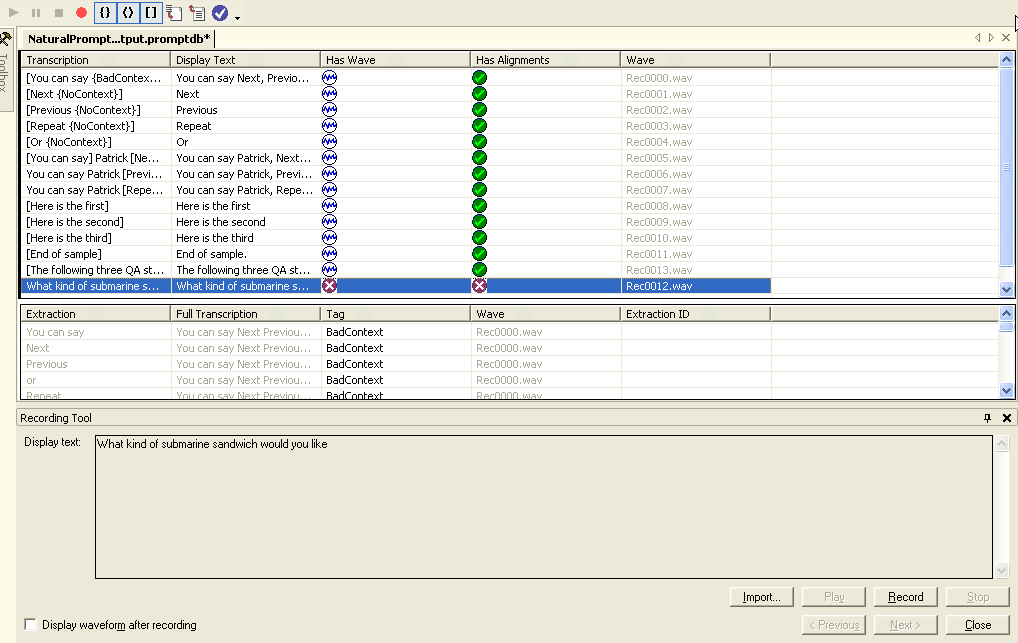
Recording a Prompt
The first step in creating a prompt is to add a new transcription using the Prompt Editor. Once this is done you can then record or import a wave file that matches the transcription exactly. For example, a transcription may be as short as a single word or as long as a single sentence. When creating transcriptions you should keep the following things in mind.
- Transcriptions are always full sentences. This makes it easier for a speaker to record with the correct voice inflections.
- Transcriptions contain no punctuation. When recording the prompt editor will automatically remove any punctuation from a transcription because they are not explicitly stated in a recording.
Once you type the sentence that will be used for transcription you can then record the prompt as shown in Figure 8. Once you've recorded the prompt the Prompt Editor will attempt to create an alignment of the sentence and the transcription as shown Figure 9. Once a successful transcription alignment is completed it is time to build extractions. This is done by selecting a series of consecutive alignments from the transcription to form an extraction. Extractions can be combined dynamically at run time to create a prompt. For example, the extractions “ham,” “roast beef,” “club,” and “sandwich” can be combined with “you ordered a” to create the prompt, “You ordered a ham sandwich.”
Once all the application prompts are recorded they are then referenced within a project to create inline prompts as shown in Figure 10. Within an application this creates a prompts file that contains only the extractions identified within the prompts database. By default, anything not marked as an extraction is not available within a referenced application. The result is that when the application runs, the prompt engine matches the prompt text in your application with the extractions in your database. If the required extraction is found it is played, otherwise the text-to-speech engine uses the system-synthesized voice to play the prompt.
Building Dynamic Prompts
Prompts can be defined statically as you saw earlier using the <prompt> tag or QuestionPrompt property of application controls. However, most speech applications tend to use dynamically defined prompts based on extractions.
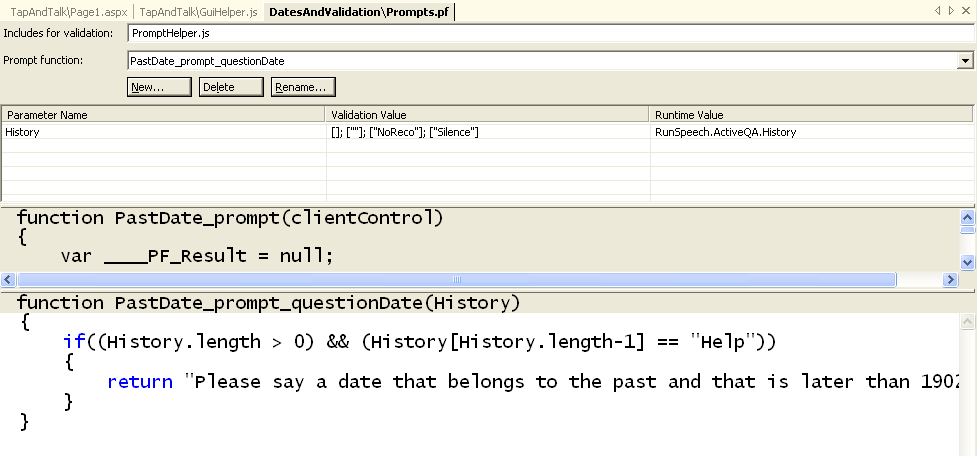
Programmatically, this is provided by the Dialog Speech Control through the PromptSelectFunction property of every Dialog and Application speech control. The PromptSelectFunction property is actually a callback function for each control that is executed on the client side. It is responsible for returning the prompt and its associated markup to use when the control is activated. This built in function enables speech applications to check and react to the current state of the dialog as shown in the following code.
function GetPromptSelectFunction() {
var lastCommandOrException = "";
var len = RunSpeech.ActiveQA.History.length;
if(len > 0) {
lastCommandOrException = RunSpeech.ActiveQA.History[len - 1];
}
if (lastCommandOrException == "Silence") {
return "Sorry I couldn't hear you. What menu selection would you?";
}
}
In this example, the PromptSelectFunction is checking the most recent voice command looking for an exception like silence. If this error is encountered, the prompt is modified to provide valid feedback to the user. PromptSelectFunction can be added inline. However, the PromptFunction Editor tool within Visual Studio is designed to manage the individual prompts and their states and is directly integrated into the Prompt Validation speech engine. This Visual Studio window is activated through the prompt function file as shown in Figure 12.
Grammar Authoring
Speech is an interactive process of prompts and commands. Semantic Markup Language Grammars are the set of structured command rules that identify words, phrases, and valid selections that are collected in response to an application prompt. Grammars provide both the exact words and the order in which the commands can be said by application users. A grammar can consist of a single word, a list of acceptable words or complex phrases. Structurally it's a combination of XML and plain text that is the result of attempting to match the user responses Within MSS, this set of data conforms to the W3C Speech Recognition Grammar Specification (SRGS). An example of a simple grammar file that allows for the selection of a sandwich is shown in Listing 4.
Listing 4: SRGS within a grammar file
<?xml version="1.0"?>
<grammar xml:lang="en-US" tag-format="semantics-ms/1.0" version="1.0" root="Root" mode="dtmf"
xmlns="http://www.w3.org/2001/06/grammar";
xmlns:sapi="http://schemas.microsoft.com/Speech/2002/06/SRGSExtensions";>
<rule id="sandwich" scope="public">
<one-of>
<item>
<item>ham</item>
<tag>$._value = "ham"</tag>
</item>
<item>
<item>roast beef</item>
<tag>$._value = "roast beef"</tag>
</item>
<item>
<item>italian</item>
<tag>$._value = "italian"</tag>
</item>
</one-of>
</rule>
</grammar>
Grammars form the guidelines that applications must use to recognize the possible commands that a user might issue. Unless the words or phrases are defined in the grammar structure, the application cannot recognize the user's speech commands and returns an error. You can think of grammar as a vocabulary of what can be said by the user and what can be understood by the application. This is like a lookup table in a database that provides a list of options to the user, rather than accepting free-form text input.
A very simple application can limit spoken commands to a single word like “open” or “print.” In this case, the grammar is not much more than a list of words. However, most applications require a richer set of commands and sentences. The user interacting with this type of speech application expects to use a normal and natural language level. This increases the expectation for any application and requires additional thought during design. For example, an application must accept, “I would like to buy a roast beef sandwich,” as well as, “Gimme a ham sandwich.”
A well-defined grammar provides a bit more functionality than that, of course. It won't just define the options, but also the additional phrases such as a preamble to a sentence. For example, the grammar corresponding to the question above must also recognize “I would like to” in addition to the option “roast beef.” So given this, the grammar is essentially a sentence or sequence of phrases broken down into their smallest component parts.
Another job of the grammar is to map multiple similar phrases to a single semantic meaning. Consider all the ways a user can ask for help. The user may say “help,” “huh,” or “what are my choices.” Ultimately, however, in all three cases the user is asking for help. The grammar is responsible for defining all three phrases and maps them to a single set of options. The benefit is that a developer only has to write the code to deal with the phrase “help.”
Implementing Grammar
Within a Visual Studio speech application, grammar files have a .grxml extension and are added independently as shown in Figure 13. Once added to a project, the Grammar Editing Tool, as shown in Figure 14, is used to add and update the independent elements. This tool is designed to provide a graphical layout using a left to right view of the phrases and rules stored in a particular grammar file. Essentially, it provides a visualization of the underlying SRGS format, in a word graph rather than the hierarchical XML.
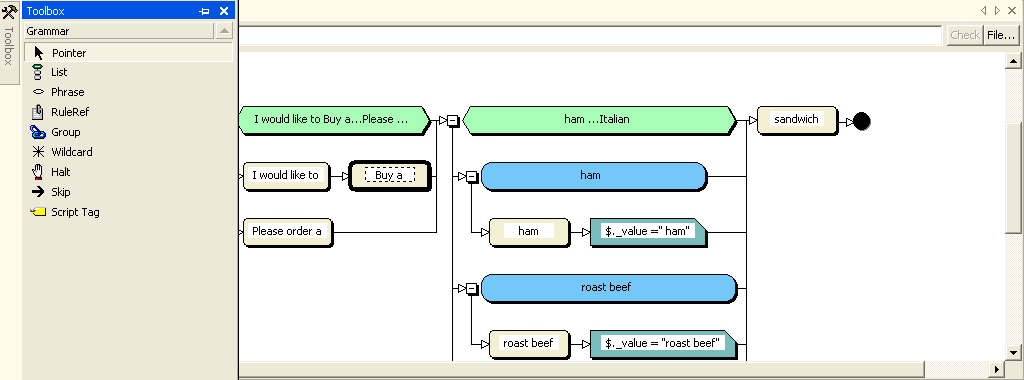
For developers, the goal of the Grammar Editor is to present a flowchart of the valid grammar paths. A valid phrase is defined by a successful path through this flowchart. Building recognition rules is done by dragging the set of toolbox elements listed in Table 2 onto the design canvas. The design canvas displays the set of valid toolbox shapes and represents the underlying SRGS elements.
During development the Grammar Editor provides the ability to show both the path of an utterance and the returned SML document as shown in Figure 15. For example, the string, “I would like to buy a ham sandwich” is entered into the Recognition string text box at the top and the path the recognizer took through the grammar is highlighted. At the bottom of the screen the build output window displays a copy of the SML document returned by the recognizer. This feature provides an important way to validate and test that both the grammar and SML document returned are accurate.
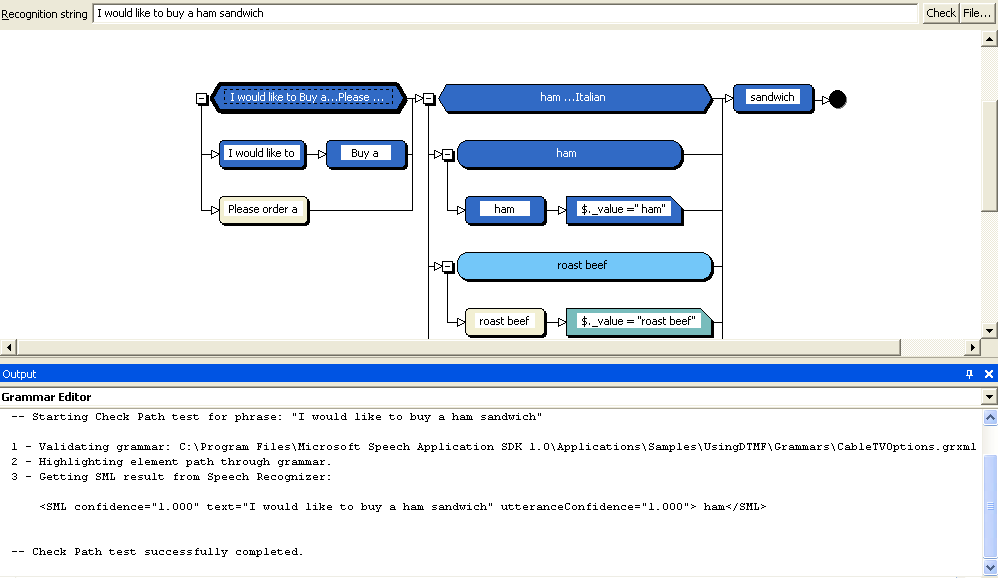
Structurally the editor provides the list of rules that identify words or phrases that an application user is able to provide. A rule defines a pattern of speech input that is recognized by the application. At run time the speech engine attempts to find a complete path through the rule using the supplied voice input. If a path is found the recognition is successful and results are returned to the application in the form of an SML document. This is an XML-based document that combines the utterance, semantic items, and a confidence value defined by the grammar as shown below.
<SML confidence="1.000" text="ham" utteranceConfidence="1.000"> ham</SML>
The confidence value is a score returned by the recognition engine that indicates the degree of confidence it has in recognizing the audio. Confidence values are often used to drive the confirmation logic within an application. For example, you may want to trigger a confirmation answer if the confidence value falls below a specific threshold such as .8.
The SASDK also includes the ability to leverage other data types as grammar within an application. The clear benefit is that you don't have to manually author every specific grammar rule. Adding these external grammars can be done through an included Grammar Library or using a process called data-driven grammar.
The Grammar Library is a reusable collection of rules provided in SRGS format that are designed to cover a variety of basic types. For example, this includes grammar for recognizing numbers and mapping holiday dates to their actual calendar dates. Data-driven grammar is a feature provided by three Application Speech controls. The ListSelector and DataTableNavigator controls enable you to take SQL Server data, bind it to the control, and automatically make all the data accessible by voice. Logically this means that you don't have to recreate all the data stored in a database into a grammar file. The third control, the AlphaDigit control, isn't a data-bound control. Rather, it automatically generates a grammar for recognizing a masked sequence. For example, the mask “DDA” would recognize any string following the format: digit, digit, character.
Application Deployment
Up to this point the discussion has focused exclusively on the development phase of speech applications using the SASDK. Ultimately, the SASDK is a faithful simulated representation of a Speech Server, coupled with additional development and debugging tools. The benefit is that when it comes time to deploy speech applications they exist as a set of ASP.NET Web pages and artifacts as shown in Table 3. Deployment is simply the process of packaging and deploying these files using the same methodology as any ASP.NET application.
However, there are some inherent architecture differences to remember between the SASDK and the Speech Server environment. For example, the Telephone Application Simulator (TASIM) provided by the SASDK is used in the development of voice-only applications. It simulates the functions of both the TAS and SES components of a Speech Server. Once the application is deployed you wouldn't be able to access voice-only applications from Internet Explorer. In a production environment, the TAS component and the SES component are completely separate. The TAS is responsible for handling the processing of incoming calls and SES handles speech input. In the development environment both of these functions are handled by the TASIM. Additionally, in the development of a multimodal application, debugging is provided by the Speech add-in for Internet Explorer, which has been enhanced to include extensions and integration with the Speech Debugger. However, these enhancements aren't available as part of the standard client installation.
Finally, when developing applications using the SASDK it is possible to build applications where the paths to grammar files are specified by physical paths. However, within the production Speech Server environment, all paths to external resources such as a grammar file must be specified using a URL not a physical path. Prior to creating your deployment package it is always a good idea to switch into HTML view and verify that all grammar file paths use a relative or absolute URL.
There are many different ways to deploy the components of Speech Server based on your usage and workload requirements. Each component is designed to work independently. This enables the deployment of single or multi-box configurations. The simplest deployment is to place the TAS, SES, IIS, hardware telephony board, and TIM software together on a single machine. Without a doubt the Web server is the essential component of any Speech Server deployment as it is the place where applications are deployed and the SALT-enabled Web content is generated. Even if you decide to deploy Speech Server components on separate Web Servers, each server running SES must have IIS enabled.
In this article you've looked at how to use the SASDK and Microsoft Speech Server 2004 to develop speech-enabled ASP.NET applications. The SASDK provides the development environment that includes a simulator and debugging tools integrated into Visual Studio 2003. This combination provides developers the ability to build and test voice and multimodal applications on their local machine. Once the application is complete, Microsoft Speech Server provides the production-level support and scalability needed to run these types of applications. Personally, I don't expect to be talking to HAL anytime soon. However, the possibilities are starting to get better.
Table 1: The standards of speech applications.
| Speech Application Language Tags (SALT) | SALT is an extension of HTML and other markup languages which adds a speech and telephony interface to Web applications. It supports both voice-only and multimodal browsers. SALT defines a small number of XML elements like the |
| Speech Recognition Grammar Specification (SRGS) | SRGS provides a way to define the phrases that an application recognizes. This includes words that may be spoken, patterns that words may occur in, and the spoken language of each word. |
| Speech Synthesis Markup Language (SSML) | SSML provides an XML-based markup language for creating the synthetic speech within an application. It enables the control of synthetic speech that includes pronunciation, volume, pitch, and rate. |
Table 2: The elements of the Grammar Editor toolbox.
| Element | Description |
|---|---|
| Phrase | The phrase element represents a single grammatical entry. |
| List | The list element specifies the relationship between a group of phrases. |
| Group | The group element binds a series of phrases together in a sequence. |
| Rule Reference | The rule reference element provides the ability to reference an external encapsulated rule. |
| Script Tag | The script tag element defines the set of valid phrases for this grammar. |
| Wild Card | The wild card element allows any part of a response to be ignored. |
| Skip | The skip element creates an optional group that can be used to insert or format semantic tags at key points in the grammar |
| Halt | The halt element immediately stops recognition when it is encountered. |
Table 3: The typical components of a speech application.
| File Type | Description |
|---|---|
| .aspx | A file containing the visual elements of a Web Forms page. |
| .ascx | A file that persists a user control as a text file. |
| .asax | A file that handles application-level events. |
| .ashx | An ASP.NET Web Handler file used to manage raw HTTP requests. |
| .grxml | A grammar file. |
| .cfg | A binary file created by the SASDK command-line grammar compiler. |
| .prompts | A compiled prompt database that is created when a .promptdb file is compiled with the Speech Prompt Editor. |
